When the Formula Is Not Enough: Numerical Stability & AI
Yesterday, I published an article on least squares:
https://dmytro.brazhnyk.org/publications/least-squares-applied-math/
That article was not really about mathematics. It was about ChatGPT — and how powerful it can be when working with well-known concepts. It demonstrated how the model can take existing ideas and present them in a clear, structured, and almost elegant way, applied to a very similar mathematical problem that I originally published a few years ago:
https://dmytro.brazhnyk.org/publications/computer-vision-car-autopilot-camera-calibration/
Today, the focus is slightly different.
This time, I want to explore where the capabilities of artificial intelligence begin to reach their limits — and where human intuition becomes necessary.
Not in opposition to AI, but as part of understanding the human role in an increasingly dynamic and ever-changing world.

Thinking about yesterday’s article and the new formula proposed by AI, one thought kept coming back to me.
The formulas looked almost identical. But what mattered more was not how they looked, but how they were computed.
In the version suggested by ChatGPT, the solution used a matrix inverse.
So I went back to my own derivation and noticed something interesting: I was solving the system using Gaussian elimination. And at the same time, matrix inversion itself is typically computed using Gaussian elimination.
So in terms of computational complexity, they seemed to be doing essentially the same thing.
I do not work with matrices and numerical methods every day, so I wanted to double-check that my understanding of the theory was still correct.
I asked two simple questions:
- What is the computational complexity of computing a matrix inverse?
- What is the complexity of Gaussian elimination?
Big-O vs Reality
ChatGPT then explained that the Big-O complexity is indeed the same in both cases. However, Gaussian elimination still performs fewer operations.
And then it pointed out something more important: the difference is not really about Big-O — it is about numerical stability.
At first, I did not fully understand what was meant.
So I asked a follow-up question:
If the Big-O is the same, can I just ignore the difference?
The answer was no. It is not really about Big-O — it is about numerical stability. And that is when it finally clicked for me.
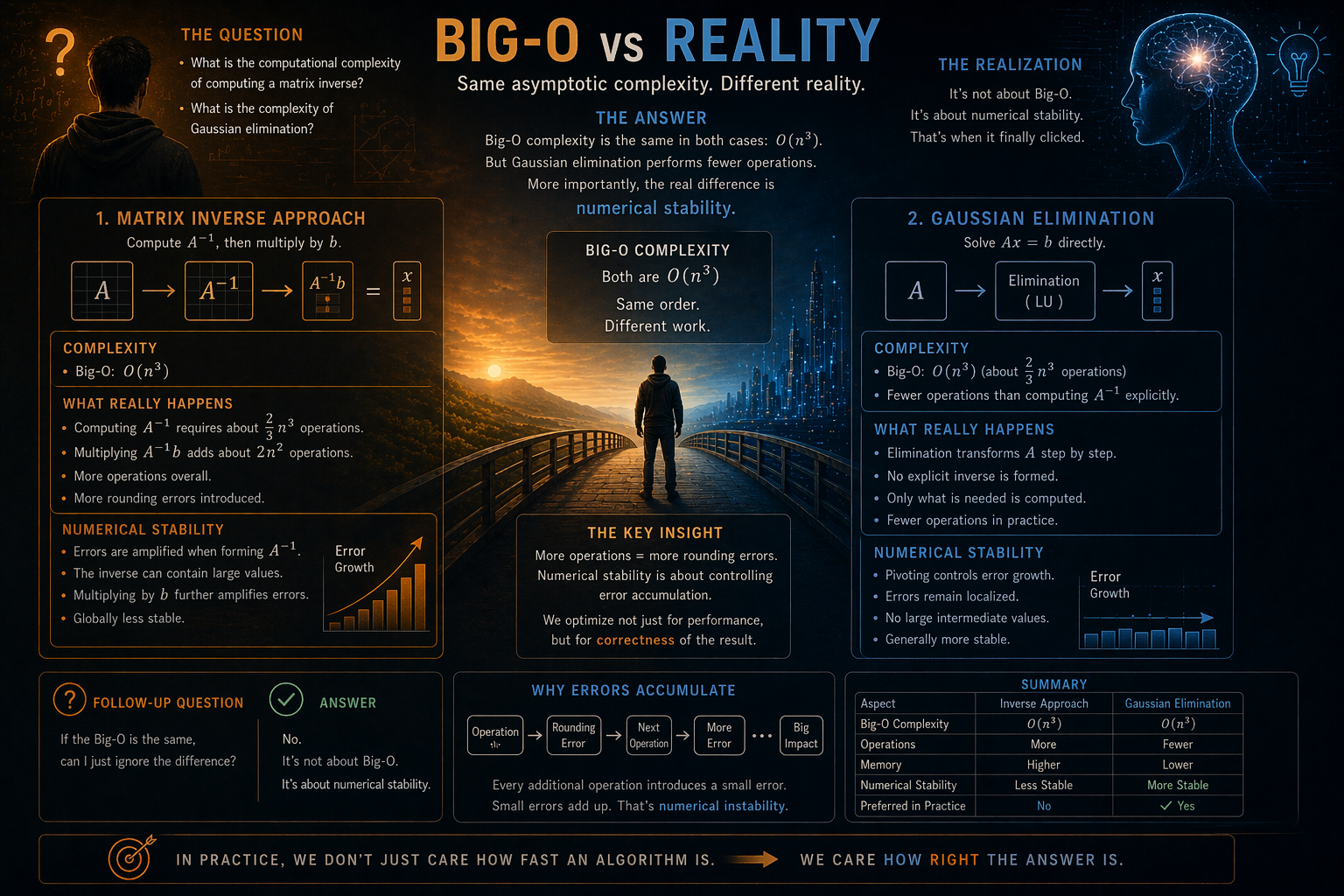
Even if two approaches are mathematically equivalent, and even if they have the same asymptotic complexity, performing more operations means introducing more rounding errors.
Every additional operation that could have been simplified at the level of a mathematical formula — but is instead executed numerically by a computer — introduces a small error.
And those errors accumulate.
That is what numerical stability really means:
- So in practice, we are not only optimizing for performance.
- We are also optimizing for correctness of the result.
A brief lyrical digression — from personal experience
For me, this is not just theory — it comes from a bitter experience: I was once eliminated from a prestigious international algorithmic competition.
The format was simple — participants were given a problem and limited time to solve it. When the jury evaluated the results, no one had a correct solution.
I remember being very confident in mine. The logic was correct, I tested it multiple times on different inputs, and everything seemed fine. So I gathered the courage to approach the jury and ask where I might have gone wrong.
They showed me one of the test cases.
My program produced something like 1.9999999999, where the expected answer was 2.0.

Exactly that.
Later, I analyzed my code and understood precisely where the issue came from — and how the computation could have been structured differently to avoid numerical instability. But at that point, it no longer mattered. My solution was not accepted.
And no one else solved the problem either.
The competition was rescheduled, and we were given the task to complete at home. The level of trust was remarkable — I am convinced that no one cheated, and I did not either.
What happened next was unexpected.
I got seriously ill and could not participate properly. At the time, I was frustrated — it felt like everything had gone wrong at the worst possible moment. But looking back now, I see it differently.
In some sense, moments like this shape our future.
If things had gone differently, I might not have what I have today. And I would not trade what I have now for anything else. I am grateful for everything that has happened in my life up to this point — and perhaps for what will come next, even if I do not yet understand it.
Some time later, I participated in another competition and became a prize winner at the national level. But by then I had realized something important.
I enjoy solving problems. I enjoy the challenge.
But I do not enjoy winning.
The most meaningful moment is right after the problem is solved — when you can talk to others, exchange ideas, and there are no winners or losers yet. Just mutual respect and shared curiosity.
That is the state I would prefer things to remain in — an atmosphere of support and respect, rather than a desire to be better than others.
ChatGPT, with its mention of numerical stability, reminded me of all of this.
Later, at university, I took a course on numerical methods, where these ideas were explained in a rigorous and scientific way. But by that time, I already had practical experience — something that stayed with me much more deeply than theory ever could.
This article is not really about my personal experience, so let’s get back to ChatGPT.
Conclusions
ChatGPT is undoubtedly a powerful tool.
But the question that naturally follows is: where are its limits?
I believe this example provides a clear answer.
In a sense, the way this experience unfolded in the article follows a classical dialectic — what Hegel would describe as thesis, antithesis, and synthesis:
- thesis — my original article on computer vision
- antithesis — where ChatGPT presents an alternative that appears not just different, but better
- synthesis — a return to the original solution, with a deeper understanding shaped through the dialogue with ChatGPT
The truth is that every time I bring something to ChatGPT, it gives me something new to learn.
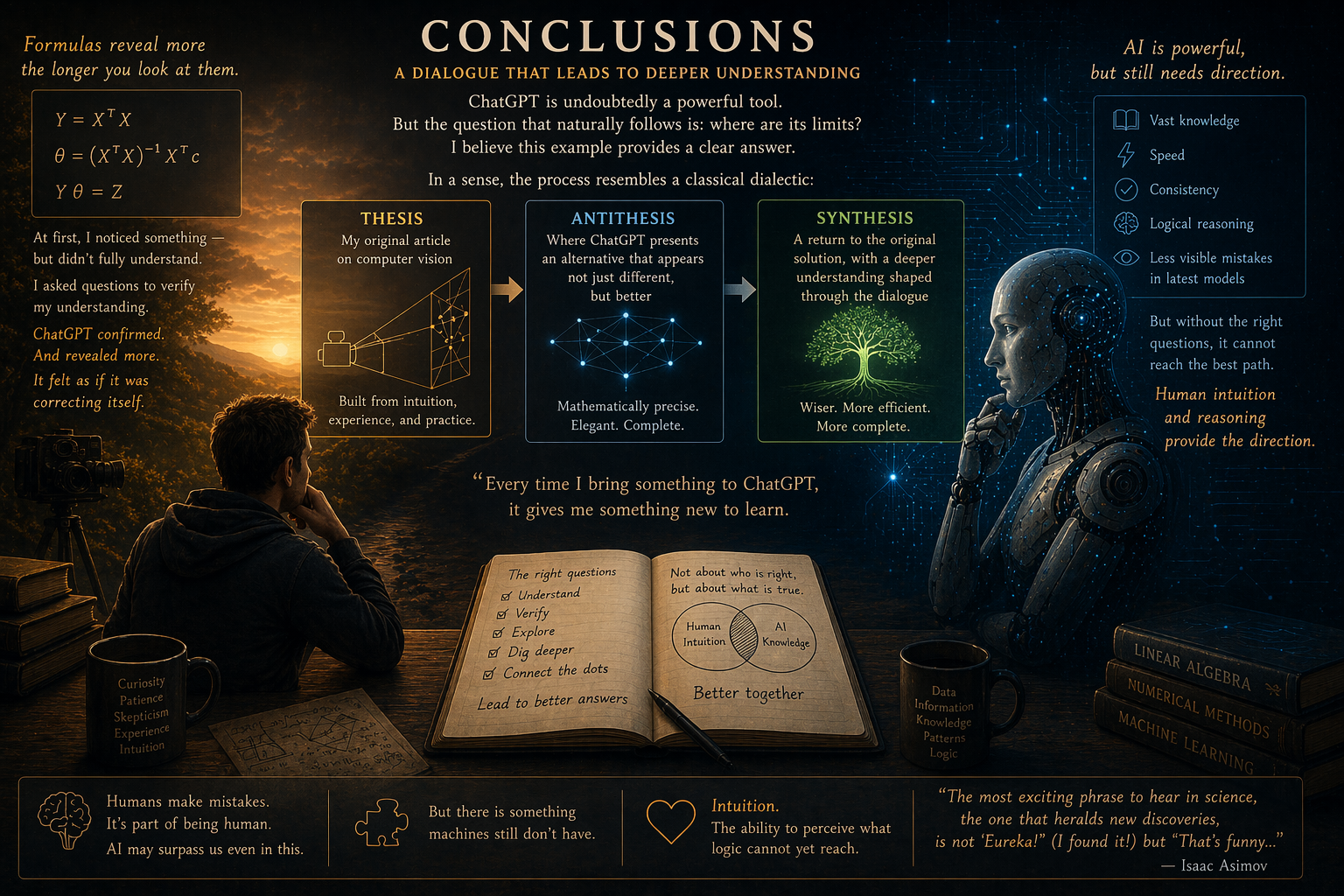
Its “antithesis” is mathematically precise — exactly as I described in the previous article. The formulas are correct, elegant, and complete.
But formulas have a particular property: they reveal more the longer you look at them.
At first, I felt that I was noticing something — but not fully understanding it. So I started asking additional questions, not to get a new answer, but to verify my own understanding.
ChatGPT confirmed what I was checking.
But at the same time, it revealed something more — something I had not initially paid attention to.
In a way, it felt as if it was correcting itself.
It is not that ChatGPT was wrong in either case — on the contrary, it helped me notice something I had not paid attention to, and gave me an opportunity to learn something new.
But there is still something that remains behind the scenes. I was not wrong from the beginning — my human intuition had already led me to a solution that was, in practice, more efficient than the one initially suggested by the AI.
But that is still not the whole picture.
Artificial intelligence was eventually able to arrive at a more efficient solution — but not without guidance. Despite being a very powerful tool, and clearly having access to far more knowledge than I do, it still required direction.
My human intuition and my human reasoning were necessary to guide and shape that process. And that only happened because I chose to ask the right questions.
Interacting with artificial intelligence feels like a very particular kind of dialogue — with something that feels human-like, something that clearly holds knowledge.
In the latest models, this has become even more apparent. AI systems are now much more consistent and formally logical than before. Earlier models made visible mistakes in reasoning quite often. Now this is far less noticeable.
But to be fair, humans also make mistakes in reasoning. In some sense, this is a very human trait. And it is entirely possible that one day, AI will surpass us even in this.
But there is something else.
Something that still feels uniquely human.
Intuition
Returning to ideas I explored in my earlier articles, I am reminded of Isaac Asimov’s work. In the books connected with the concept of Gaia, he describes characters — such as Golan Trevize — who possess a unique ability to make the right decisions without having complete information.
Isaac — what an incredible author he is.
Long before the emergence of modern artificial intelligence, he was already trying to define something difficult to capture — intuition. And he suggested that this might be exactly what machines lack, in contrast to humans.

Artificial intelligence — somewhere between good and evil
This is the feeling I have when working with it today.
Human intuition — the ability to understand things that cannot be fully captured by logic — may well be the boundary that artificial intelligence cannot cross. I do not say this to suggest that the technology is limited or destined to fail. On the contrary, I say this to remove a certain kind of misplaced fear — the fear of a future technology that is already part of our present, and the fear that it will replace or push humans aside.
Perhaps I am also writing this so that people stop blaming technology — and especially artificial intelligence — for problems that already exist, and instead, when something goes wrong, try to understand the true nature of things.

The main conclusion, for me, is intuition.
One of the most meaningful sources that helped me reflect on what intuition is — and where it comes from — has been the Bible. I am skeptical that the scientific method alone will ever fully explain the nature of the human mind.
Understanding a human being may require a different level of insight — something closer to the perspective of an artist than that of a scientist. And perhaps the attempt to reach that level is part of the same journey that, in a symbolic sense, is described as leaving Eden.
But even on that path, I do not believe that humanity is left alone.
Just as parents watch their children grow — sometimes with concern, but also with love — there is meaning in the process of learning, exploring, and becoming.
Every time a child learns something new, a loving parent rejoices.
In the same way, when humans create something that appears intelligent, it is not something to fear, but something to understand. It is an expression of creativity — a reflection of the very nature that was given to us.
A loving Father — God — would rejoice to see us use the talents He has given us.
Artificial intelligence is not evil in itself.
Like any powerful tool, it must be learned, understood, and used for good — much like fire once became an essential companion to humanity.
With that, I will conclude this reflection and move on to the work itself.
The rest of this text, as in the previous article, is generated with the help of artificial intelligence.
Enjoy reading.
Where the Two Articles Meet — Same Formula, Two Interpretations
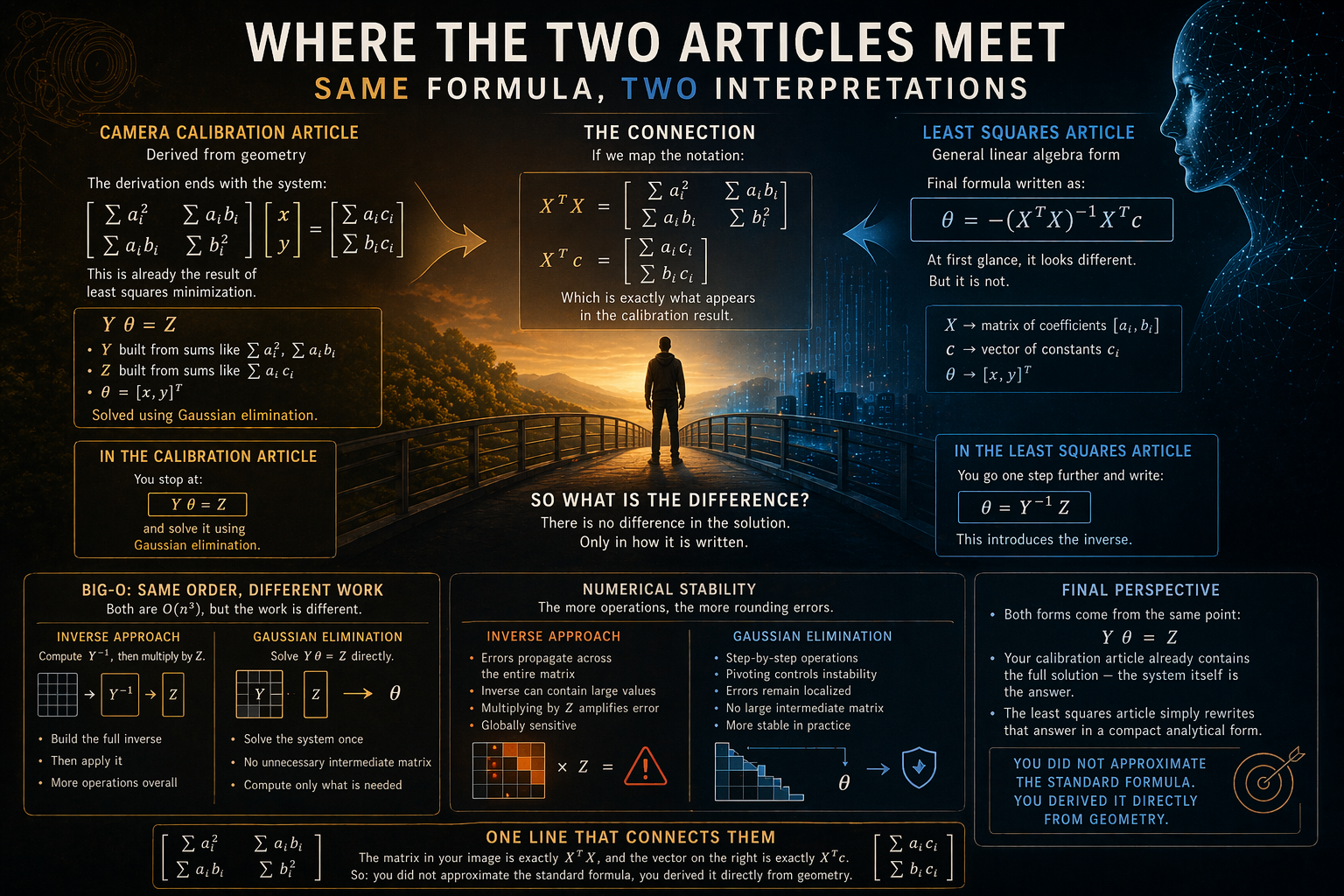
In the original camera calibration article, the derivation ends with the following system:
https://dmytro.brazhnyk.org/publications/computer-vision-car-autopilot-camera-calibration/
This is already the result of the least squares minimization.
At this point, we are no longer dealing with geometry. We have a linear system of the form:
where:
is built from sums like is built from sums like
This is the complete solution, just written implicitly.
The Same Result in the Least Squares Article
In yesterday's least squares article, the final formula is written as:
https://dmytro.brazhnyk.org/publications/least-squares-applied-math/
At first glance, this looks different.
But it is not.
The Connection
If we map the notation:
→ matrix of coefficients → vector of constants
then:
and
Which is exactly what appears in your calibration result.
So What Is the Difference?
There is no difference in the solution.
Only in how it is written.
In the calibration article
You stop at:
and solve it using Gaussian elimination.
In the least squares article
You go one step further and write:
This introduces the inverse.
The Key Insight
Both forms come from the same point:
- Gaussian elimination → computes the solution
- Inverse → describes the solution
Why This Distinction Matters
Even though:
- both are mathematically equivalent
- both have
complexity
they are not the same computationally.
Big-O: Same Order, Different Work
Big-O notation describes how the cost grows with input size, but it does not describe how the work is done.
In the inverse-based approach:
- we compute
, which effectively requires solving the system multiple times - then we multiply the result by
So the work is split into two stages:
- build the full inverse
- apply it
In the Gaussian elimination approach:
- we directly solve
once - no unnecessary intermediate matrix is created
Both approaches scale as
one computes everything, the other computes only what is needed
Numerical Stability
The more important difference appears when we consider real computations.
Computers use floating-point arithmetic, which introduces small rounding errors at every step.
The key question is:
do these errors remain small, or do they grow?
Structure of the problem
In least squares, the matrix is:
This has an important consequence:
if
is ill-conditioned, then is significantly worse
In practice, the condition number often grows roughly as:
So the system is already sensitive before solving.
Inverse approach
When computing:
- small errors propagate across the entire matrix
- the inverse can contain large values
- multiplying by
amplifies the error further
This makes the computation globally sensitive.
Gaussian elimination
When solving:
- operations are performed step by step
- pivoting helps control instability
- errors remain more localized
- no large intermediate matrix is created
This makes the computation more stable in practice.
Final Perspective
Your calibration article already contains the full solution:
the system itself is the answer
The least squares article simply rewrites that answer in a compact analytical form.
One Line That Connects Them
The matrix in your image is exactly
and the vector on the right is exactly
So:
you did not approximate the standard formula,
you derived it directly from geometry.