Introduction
These days, everyone is talking about AI.
Recently, I was working on an engineering problem and decided to ask ChatGPT for help with some of the mathematics behind it. Interestingly, from a mathematical perspective, it suggested something very close to what I had already implemented earlier in this work:
https://dmytro.brazhnyk.org/publications/computer-vision-car-autopilot-camera-calibration/

That experience led me down a slightly different path.
During my academic studies, we had a solid course in differential equations in general, and gradients were covered well. Differentiation for matrices was also explained properly, though quite quickly due to time constraints, so it never became a major focus in the curriculum — I still graduated as a computer scientist with a focus on software engineering, not as a pure mathematician.
Much of what I know about matrices, tensors, and their role in more advanced mathematics comes from self-study — both before entering university and after graduation. There was a time when I was still a kid, deeply curious and already exploring advanced mathematics on my own, especially linear algebra in the context of computer graphics.
Over the past few days, I spent quite a bit of time discussing these topics with ChatGPT — trying to better understand how differentiation extends to matrices and tensors.
What genuinely impressed me is not that it solves problems differently, but how the same ideas I had already used can be expressed in a much more compact and structured way. Matrix notation does not change the solution itself — it allows what previously required longer and more explicit formulas to be written in just a few concise expressions.
It simplifies the mathematical description of what would otherwise be quite heavy and verbose, while the underlying complexity of the solution remains the same.
After these conversations, I ran a small experiment.
I asked ChatGPT to generate an article based on what we had discussed over the past few days. I provided some context — that this was a problem I had already solved — and suggested approaching it not from a software engineering perspective, but from a more mathematical one.
This is an area where I genuinely feel there is still room for my own growth.
I was curious to see whether ChatGPT could take the context of several days of open-ended discussion — conversations that were never intended to produce an article, but were instead driven by genuine learning — and turn it into a meaningful, self-contained piece with its own structure, boundaries, and goals.
Everything below was entirely generated by ChatGPT — not my writing, only a few minor adjustments after my review. In my honest opinion, the writing is quite decent.
This is not new mathematical research — least squares optimization is well known in mathematics. The point here is not novelty, but capability: ChatGPT is not creating new mathematics, but it operates very effectively within what is already known.
It doesn’t invent new concepts, but it can organize and express existing ones in a clear and compact way. That alone already makes AI a very powerful tool.
Enjoy the reading.
How a Mathematician Would See This Problem (and Why It’s the Same Result)
In the previous part, we solved the problem in the most straightforward way possible.
We had a very concrete task:
find a point on the image that best represents the direction of the car’s movement, based on a large number of optical flow vectors.
We didn’t try to be elegant. We simply:
- wrote down the line equation for each vector
- defined distance to a point
- summed squared distances
- took derivatives
- solved the resulting system
This is a very engineering-style approach. It works. It’s transparent. And most importantly — it leaves no room for “magic”.
But there is another way to look at the same thing.
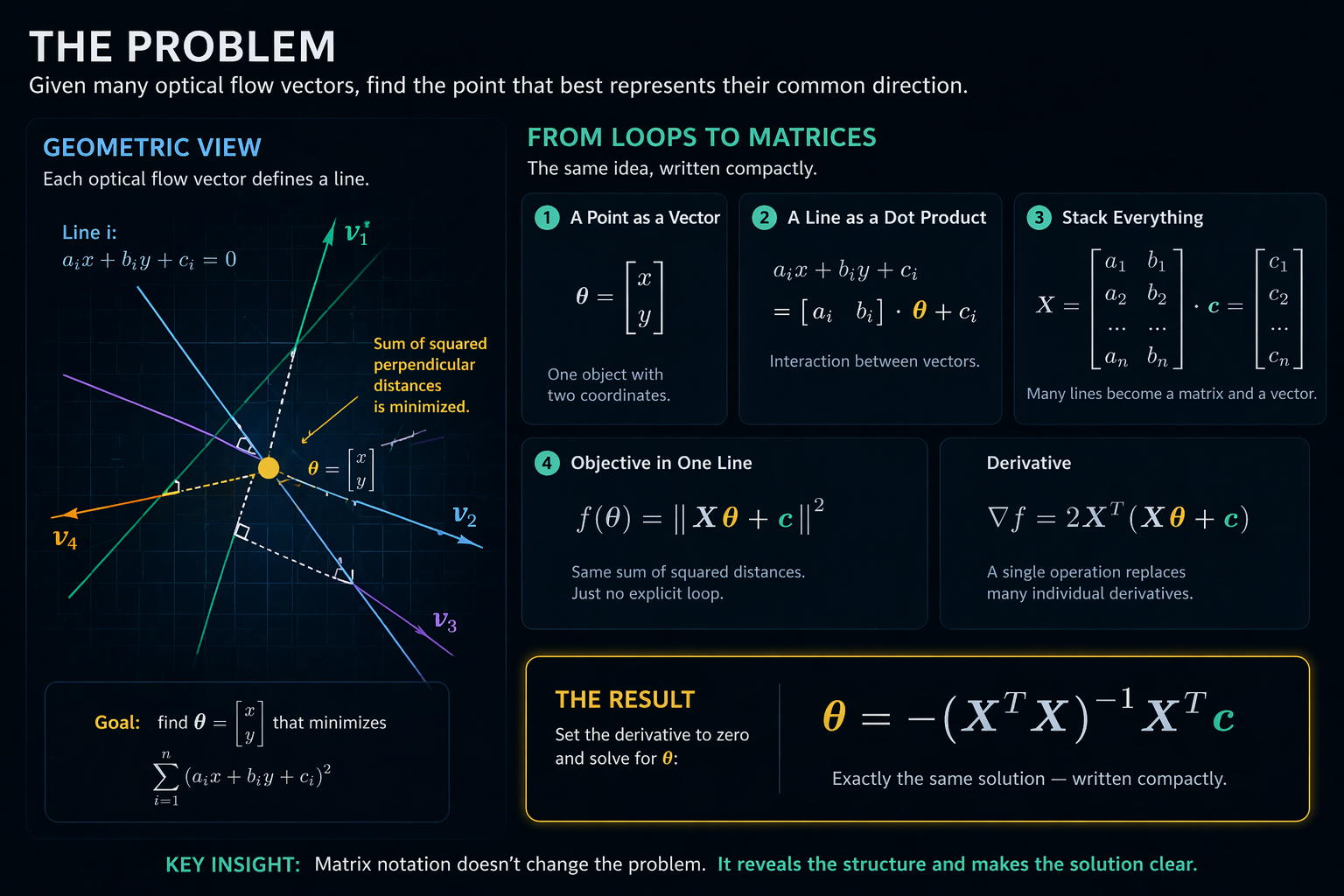
A Point Is Not Two Variables
When we write:
it feels like two independent variables.
A mathematician sees it differently:
this is a single object with two coordinates.
So instead of thinking in terms of x and y, we introduce a vector:
Nothing changes — but the perspective does.
A Line Is Not Just a Formula
We originally wrote:
But the expression
It is a dot product:
So each line becomes:
Each line is no longer just an equation — it is an interaction between vectors.
The Whole Problem Is Repetition
If you look at the full objective:
you start to notice a pattern:
- take a vector
- multiply by another vector
- add a constant
- square it
- repeat many times
At this point, it looks less like geometry and more like data processing.
The Natural Step: Compress It
If you're an engineer, you look at this and think:
this can be vectorized
A mathematician does the same — just without calling it that.
All vectors [a_i, b_i] are stacked into a matrix:
All constants c_i go into a vector:
Suddenly, Everything Becomes Compact
What used to be a loop becomes a single expression:
And the objective becomes:
Same logic. Just no explicit loop.
Derivative as a Single Operation
Recall the intuition:
Here:
\(\theta\)is a vector\(d\theta\)is a small change\(f'\)is something that turns that change into a scalar
And again, this “something” turns out to be a vector.
The Result
The Final Step: Solving for θ
We set the derivative to zero:
Rearranging:
And finally:
Closing Thought
What looks like “matrix magic”:
is actually just a compact way to write a large number of simple operations.
And this is the point where mathematics stops being abstract — and starts to look like well-optimized code.
That expression:
is not a new method.
It is exactly the same thing you already implemented —
just written as a single line instead of a few dozen operations.